【Advanced Java】搜索引擎
ES简介
elasticsearch 是基于 lucene /luːsɪŋ/ 的搜索库,分布式的文档存储,搜索,分析,支持 PB 级数据。
下面是 ES 里的一些概念
- Near Real Time,近实时
- 写入数据到数据可以被搜索有一个小延迟(大概是 1s)
- 基于 es 执行搜索和分析可以达到秒级
- Cluster 集群
- Node 节点
- Document & field
- document 是一条 record
- field
- Index 索引,一个索引包含很多 document
- Type,一个索引里有一个或者多个 type
- shard,把一个索引中的数据切分成多个 shard
- replica,shard 分为 primary shard 和 replica shard
ES 如何实现分布式
ES shard 来实现分布式。
- 支持横向扩展
- 提高性能
ES 工作原理
写数据
- client 发送请求到 coordinating node
- coordinating node 对 document 路由,转发给对应的 primary shard
- primary 同步到 replica node,完成后响应结果
读数据
- client 发送请求到 coordinating node
- client 路由,负载均衡到相应的 node(随机轮询算法)
- node 返回到 coordinating node,完成后响应结果
es搜索
- client 发送到 coordinating node
- coordinating node 转发到所有的 shard(primary 或 replica)
- query phase:shard 返回 doc id 给 coordinating node,coordinating node 对结果合并,排序,分页等操作,产出最终结果
- fetch phase:由 coordinating node 根据 doc id 来拉取实际的 document 数据
es写数据底层原理
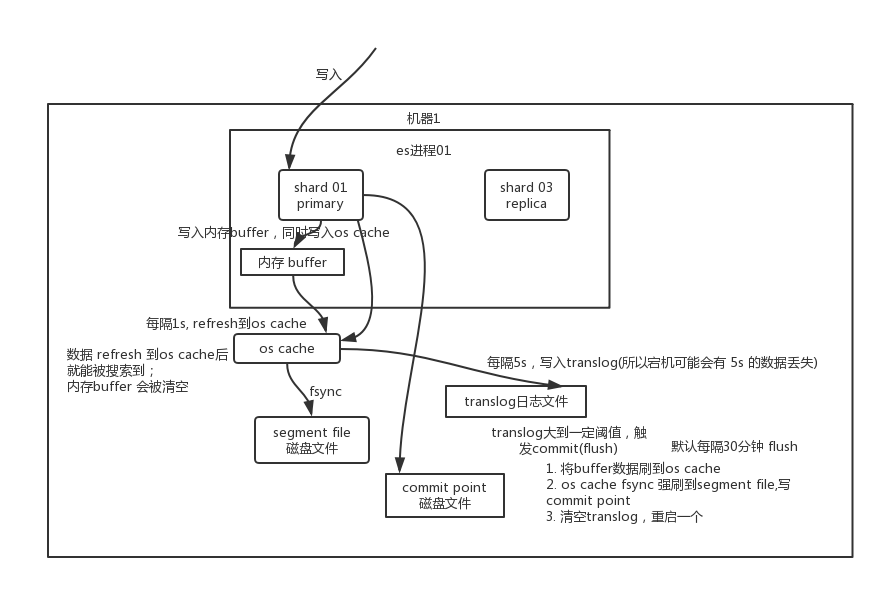
因此是 1s 的准实时,5s 的数据丢失。
es删除/更新数据底层原理
如果是删除操作,commit 的时候会生成一个 .del 文件,里面将某个 doc 标识为 deleted 状态,那么搜索的时候根据 .del 文件就知道这个 doc 是否被删除了。
如果是更新操作,就是将原来的 doc 标识为 deleted 状态,然后新写入一条数据。
buffer 每 refresh 一次,就会产生一个 segment file,所以默认情况下是 1 秒钟一个 segment file,这样下来 segment file 会越来越多,此时会定期执行 merge。每次 merge 的时候,会将多个 segment file 合并成一个,同时这里会将标识为 deleted 的 doc 给物理删除掉,然后将新的 segment file 写入磁盘,这里会写一个 commit point,标识所有新的 segment file,然后打开 segment file 供搜索使用,同时删除旧的 segment file。
ES 优化
- filesystem cache
- 加内存
- document 太大,可以 es + hbase
- 数据预热
- 冷热分离,不要让冷数据冲刷掉热数据
- 不用分页,向微博一样用 scroll