【Advanced Java】消息队列
为什么要用消息队列
优点:
- 解耦,producer 无需关心 consumer
- 异步,consumer 异步写库
- 削峰,高峰期
缺点:
- 可用性降低
- 复杂度提高。重复消费,消息丢失,消息顺序性
- 一致性
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 单机吞吐量 | 万级,比 RocketMQ、Kafka 低一个数量级 | 同 ActiveMQ | 10 万级,支撑高吞吐 | 10 万级,高吞吐,一般配合大数据类的系统来进行实时数据计算、日志采集等场景 |
| topic 数量对吞吐量的影响 | topic 可以达到几百/几千的级别,吞吐量会有较小幅度的下降,这是 RocketMQ 的一大优势,在同等机器下,可以支撑大量的 topic | topic 从几十到几百个时候,吞吐量会大幅度下降,在同等机器下,Kafka 尽量保证 topic 数量不要过多,如果要支撑大规模的 topic,需要增加更多的机器资源 | ||
| 时效性 | ms 级 | 微秒级,这是 RabbitMQ 的一大特点,延迟最低 | ms 级 | 延迟在 ms 级以内 |
| 可用性 | 高,基于主从架构实现高可用 | 同 ActiveMQ | 非常高,分布式架构 | 非常高,分布式,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 |
| 消息可靠性 | 有较低的概率丢失数据 | 基本不丢 | 经过参数优化配置,可以做到 0 丢失 | 同 RocketMQ |
| 功能支持 | MQ 领域的功能极其完备 | 基于 erlang 开发,并发能力很强,性能极好,延时很低 | MQ 功能较为完善,还是分布式的,扩展性好 | 功能较为简单,主要支持简单的 MQ 功能,在大数据领域的实时计算以及日志采集被大规模使用 |
高可用
HA, HighAvailability
RabbitMQ
- 单机模式
- 普通集群模式(无高可用)。数据在一台实例上,其他的同步 queue 元信息(用元信息找到存放数据的实例)
- 镜像集群模式
Kafka
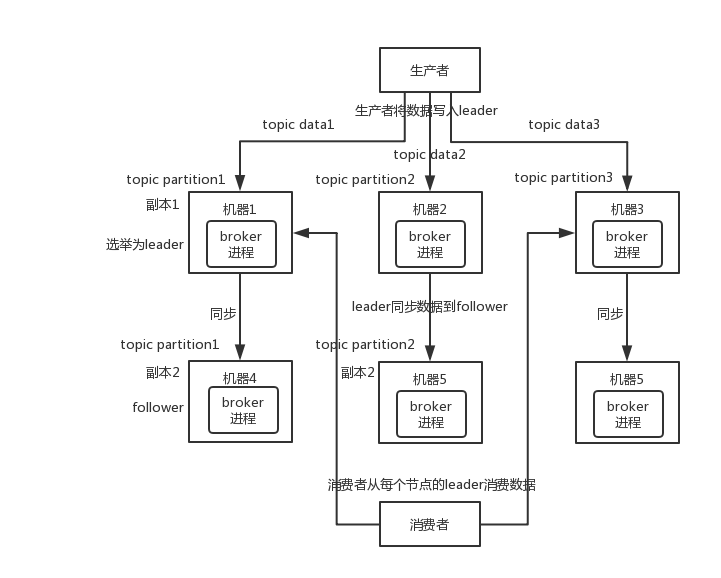
写数据的时候,生产者就写 leader,然后 leader 将数据落地写本地磁盘,接着其他 follower 自己主动从 leader 来 pull 数据。一旦所有 follower 同步好数据了,就会发送 ack 给 leader,leader 收到所有 follower 的 ack 之后,就会返回写成功的消息给生产者。(当然,这只是其中一种模式,还可以适当调整这个行为)
消费的时候,只会从 leader 去读,但是只有当一个消息已经被所有 follower 都同步成功返回 ack 的时候,这个消息才会被消费者读到。
重复消费
通常由下游保证。
可靠消息
- 生产者丢了 => MQ ack
- MQ 丢了 => MQ ack until persistence completion
- consumer 丢了 => consumer ack
消费积压
- 紧急扩容,加速消费
- 大量积压快过期了,可以先批量重导
设计一个 MQ
- 可伸缩性,broker->topic->partition
- 可靠性,持久化到磁盘,顺序写
- 可用性,leader->follower